
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Binding
- MS-SQL
- GitHub
- Firebase
- typescript
- 함수
- AnimationController
- 바인딩
- React JS
- Maui
- listview
- Flutter
- 자바스크립트
- 애니메이션
- spring boot
- MSSQL
- HTML
- db
- 파이어베이스
- JavaScript
- 닷넷
- MVVM
- Animation
- 오류
- .NET
- page
- 깃허브
- 마우이
- 플러터
- 리엑트
- Today
- Total
개발노트
20. [MS-SQL] RDBMS 고려사항들 본문
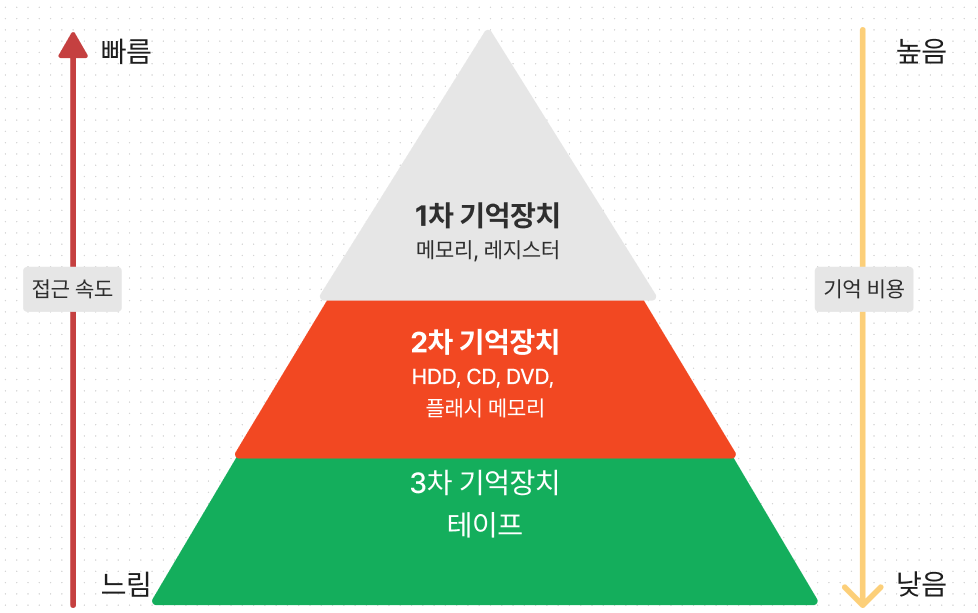
기억장치 성능, 비용 그래프
데이터베이스 시스템에서 데이터 캐시와 로그 버퍼 이해하기
1. 데이터 캐시 (Buffer Cache)
- 데이터 캐시는 디스크에 저장된 데이터 페이지를 메모리에 캐싱하는 메커니즘입니다. 이를 통해 동일한 데이터를 반복적으로 디스크에서 읽어오는 대신 메모리에서 빠르게 접근할 수 있습니다.
역할
- 디스크 I/O 감소: 디스크에 접근하는 횟수를 줄여 성능을 향상시킵니다.
- 빠른 데이터 접근: 메모리에서 데이터를 읽는 것이 디스크에서 읽는 것보다 훨씬 빠릅니다.
동작 방식
- 읽기 작업: 데이터베이스는 디스크에서 데이터를 읽기 전에 먼저 데이터 캐시에 해당 데이터가 있는지 확인합니다. 캐시에 있으면 디스크 접근 없이 데이터를 메모리에서 가져옵니다.
- 쓰기 작업: 데이터베이스는 변경된 데이터를 먼저 데이터 캐시에 기록하고 나중에 비동기적으로 디스크에 기록합니다.
2. 로그 버퍼 (Log Buffer)
개념
- 로그 버퍼는 트랜잭션 로그 기록을 메모리에 저장하는 버퍼입니다. 트랜잭션 로그는 데이터베이스의 변경 사항을 기록하여 데이터 일관성과 복구 기능을 지원합니다.
역할
- 트랜잭션 관리: 트랜잭션이 발생할 때마다 변경 사항을 로그 버퍼에 기록하여 데이터베이스의 일관성을 유지합니다.
- 데이터 복구: 시스템 장애 발생 시 로그 버퍼에 기록된 내용을 통해 데이터 복구를 지원합니다.
동작 방식
- 트랜잭션 시작: 트랜잭션이 시작되면, 변경 사항이 로그 버퍼에 기록됩니다.
- 커밋: 트랜잭션이 커밋되면 로그 버퍼에 저장된 로그가 디스크의 트랜잭션 로그 파일에 기록됩니다.
- 플러시: 로그 버퍼가 가득 차거나 특정 조건이 만족되면 버퍼의 내용이 디스크에 기록됩니다.
데이터 캐시와 로그 버퍼의 상호작용
데이터 캐시와 로그 버퍼는 데이터베이스의 성능을 최적화하고 데이터 일관성을 유지하기 위해 상호작용합니다.
상호작용 과정:
- 읽기 요청: 사용자가 데이터를 요청하면 데이터베이스는 먼저 데이터 캐시를 확인하고, 데이터가 있으면 캐시에서 직접 제공합니다. 데이터가 없으면 디스크에서 데이터를 읽어와 캐시에 저장한 후 제공합니다.
- 쓰기 요청: 사용자가 데이터를 변경하면 데이터베이스는 데이터 캐시에 변경된 데이터를 저장하고, 동시에 로그 버퍼에 트랜잭션 로그를 기록합니다.
- 커밋: 트랜잭션이 커밋되면 로그 버퍼에 있는 로그가 디스크에 저장됩니다. 이후 데이터 캐시에 있는 데이터도 비동기적으로 디스크에 기록됩니다.
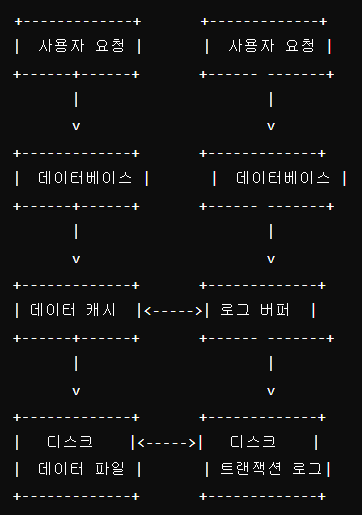
- 읽기 요청:
- 사용자 요청이 데이터베이스에 도달하면, 데이터베이스는 데이터 캐시에서 요청된 데이터를 찾습니다.
- 데이터 캐시에 데이터가 있으면, 데이터를 사용자에게 반환합니다.
- 데이터 캐시에 데이터가 없으면, 디스크에서 데이터를 읽어와 데이터 캐시에 저장한 후 사용자에게 반환합니다.
- 쓰기 요청:
- 사용자 요청이 데이터베이스에 도달하면, 데이터베이스는 데이터 캐시에 데이터를 저장하고 로그 버퍼에 트랜잭션 로그를 기록합니다.
- 트랜잭션이 커밋되면 로그 버퍼의 내용이 디스크의 트랜잭션 로그 파일에 기록됩니다.
- 데이터 캐시의 데이터는 비동기적으로 디스크의 데이터 파일에 기록됩니다.
결론
데이터 캐시와 로그 버퍼는 데이터베이스 시스템의 성능 최적화와 데이터 일관성을 유지하는 데 중요한 역할을 합니다.
데이터 캐시는 데이터 페이지의 읽기 및 쓰기 성능을 최적화하고, 로그 버퍼는 트랜잭션 로그 기록의 성능을 최적화하여 데이터 일관성과 복구 기능을 지원합니다.
이를 통해 데이터베이스는 효율적으로 작동하며, 사용자는 더 빠른 응답 속도를 경험할 수 있습니다.
부분 범위 처리와 전체 범위 처리에 대한 설명과 MSSQL 예제를 들어 설명하겠습니다.
이는 데이터베이스에서 쿼리를 최적화하고 성능을 개선하는 방법에 대한 중요한 주제입니다.
전체 범위 처리 (Full Range Scan)
전체 범위 처리는 테이블의 모든 행을 읽어서 조건에 맞는 데이터를 찾는 방식입니다. 이는 일반적으로 인덱스가 없거나 인덱스를 사용할 수 없는 경우 발생합니다.
예시: 다음은 전체 범위 처리를 수행하는 쿼리의 예입니다.
SELECT * FROM Employees WHERE LastName = 'Smith';만약 Employees 테이블에 LastName 열에 인덱스가 없으면, MSSQL은 테이블의 모든 행을 읽어서 LastName이 'Smith'인 행을 찾습니다. 이는 전체 범위 처리를 의미합니다.
설명:
- 장점: 모든 데이터를 조회할 수 있어 특정 인덱스에 의존하지 않습니다.
- 단점: 큰 테이블에서 매우 비효율적이며, 조회 시간이 길어질 수 있습니다.
부분 범위 처리 (Index Range Scan)
부분 범위 처리는 인덱스를 사용하여 테이블의 특정 부분만 읽는 방식입니다.
이는 훨씬 더 효율적이며, 특정 조건에 맞는 데이터를 빠르게 찾을 수 있습니다.
예시: 다음은 부분 범위 처리를 수행하는 쿼리의 예입니다.
-- 먼저 LastName 열에 인덱스를 생성합니다.
CREATE INDEX idx_LastName ON Employees(LastName);
-- 인덱스를 사용하여 특정 데이터를 조회합니다.
SELECT * FROM Employees WHERE LastName = 'Smith';Employees 테이블의 LastName 열에 인덱스가 생성된 상태에서 위의 쿼리를 실행하면, MSSQL은 idx_LastName 인덱스를 사용하여 'Smith'인 행들만 빠르게 조회할 수 있습니다. 이는 부분 범위 처리를 의미합니다.
설명:
- 장점: 필요한 데이터만 빠르게 조회할 수 있어 성능이 향상됩니다.
- 단점: 인덱스를 유지 관리해야 하며, 인덱스를 생성하고 업데이트하는 데 추가 비용이 발생합니다.
LIKE 문과 와일드카드를 사용할 때의 인덱스 사용 여부는 와일드카드의 위치에 따라 달라집니다.
일부 경우에는 부분 범위 처리를 통해 인덱스를 사용할 수 있지만, 다른 경우에는 전체 범위 처리가 필요할 수 있습니다.
와일드카드 사용에 따른 인덱스 처리 방식
1. 부분 범위 탐색이 가능한 경우
1-1) 와일드카드가 뒤에 있는 경우:
SELECT * FROM Employees WHERE LastName LIKE 'Smith%';- 인덱스를 사용할 수 있습니다. 이는 부분 범위 탐색으로 처리될 수 있습니다.
- 예시: LIKE 'Smith%'
- 이 경우, 인덱스가 있는 LastName 열을 사용하여 'Smith'로 시작하는 모든 행을 빠르게 찾을 수 있습니다.
2. 전체 범위 탐색이 필요한 경우
2-1) 와일드카드가 앞에 있는 경우:
SELECT * FROM Employees WHERE LastName LIKE '%Smith';-
- 인덱스를 사용할 수 없습니다. 전체 범위 탐색이 필요합니다.
- 예시: LIKE '%Smith'
- 이 경우, 'Smith'로 끝나는 모든 행을 찾기 위해 테이블의 모든 행을 검색해야 합니다.
2-2) 와일드카드가 앞뒤에 있는 경우:
-
SELECT * FROM Employees WHERE LastName LIKE '%Smith%';- 인덱스를 사용할 수 없습니다. 전체 범위 탐색이 필요합니다.
- 예시: LIKE '%Smith%'
- 이 경우, 'Smith'가 포함된 모든 행을 찾기 위해 테이블의 모든 행을 검색해야 합니다.
요약
- 부분 범위 탐색:
- LIKE 'Smith%' 와 같이 와일드카드가 뒤에 있는 경우, 인덱스를 사용할 수 있어 성능이 향상됩니다.
- 전체 범위 탐색:
- LIKE '%Smith' 또는 LIKE '%Smith%' 와 같이 와일드카드가 앞에 있거나 양쪽에 있는 경우, 인덱스를 사용할 수 없어 전체 테이블을 검색해야 합니다.
이 차이를 이해하고 적절히 활용하면, 데이터베이스 쿼리 성능을 크게 개선할 수 있습니다.
인덱스를 사용하면 탐색 속도는 빠르지만, 랜덤접근을 하기 때문에 여러 디스크를 탐색하게 되고,
이에 따라 디스크 I/O 횟수에도 신경을 써야합니다.
순차 접근 vs. 랜덤 접근
- 순차 접근(Sequential Access):
- 데이터를 처음부터 끝까지 하나씩 순서대로 읽어 나가는 방식입니다.
- 예를 들어, 테이블의 모든 레코드를 처음부터 순서대로 읽는 것을 의미합니다.
- 순차 접근은 디스크 입출력 비용이 상대적으로 낮습니다.
- 랜덤 접근(Random Access):
- 특정 위치의 데이터를 직접 접근하는 방식입니다.
- 예를 들어, 테이블에서 특정 조건을 만족하는 데이터를 바로 찾아 읽어오는 것을 의미합니다.
- 인덱스를 사용하면 원하는 데이터를 빠르게 찾을 수 있지만, 디스크의 여러 위치를 건너뛰며 읽기 때문에 디스크 입출력 비용이 더 높을 수 있습니다.
인덱스의 역할
인덱스는 데이터베이스 테이블의 특정 열(column)에 대한 정보를 미리 정렬하여 저장해 둠으로써, 원하는 데이터를 빠르게 찾을 수 있도록 도와줍니다. 인덱스를 사용하면 전체 테이블을 순차적으로 읽지 않고도 원하는 데이터를 빠르게 찾을 수 있습니다. 이는 일종의 "랜덤 접근"을 가능하게 합니다.
장점과 단점
- 장점:
- 데이터를 빠르게 검색할 수 있습니다.
- 특정 조건을 만족하는 데이터를 신속하게 조회할 수 있습니다.
- 단점:
- 인덱스를 사용하는 경우, 디스크의 여러 위치를 건너뛰면서 데이터를 읽기 때문에 디스크 입출력(IO) 비용이 높아질 수 있습니다.
- 즉, 순차적으로 데이터를 읽는 것보다 성능이 떨어질 수 있습니다.
예를 들어, 다음과 같은 SQL 쿼리가 있다고 가정해 봅시다.
SELECT * FROM employees WHERE employee_id = 12345;
이 쿼리는 employee_id 열에 인덱스가 있는 경우, 인덱스를 사용하여 해당 직원의 데이터를 빠르게 찾을 수 있습니다.
이 경우 전체 employees 테이블을 순차적으로 읽을 필요 없이, 바로 해당 직원의 데이터를 읽어오는 "랜덤 접근"을 하게 됩니다.
따라서, 테이블 데이터를 랜덤하게 접근한다는 말은 인덱스를 활용하여 원하는 데이터를 빠르게 찾는 방식이지만, 그 과정에서 디스크 입출력 비용이 높아질 수 있다는 의미입니다.
트레이드오프 (Trade-off)
트레이드오프는 특정 성능 또는 기능을 향상시키기 위해 다른 성능 또는 기능을 포기해야 하는 상황을 의미합니다. 데이터베이스 시스템에서도 다양한 트레이드오프가 존재합니다.
주요 트레이드오프:
- 성능 vs. 데이터 일관성: 성능을 높이기 위해 데이터 일관성을 약간 희생할 수 있습니다. 예를 들어, 캐시를 사용하면 읽기 성능이 향상되지만, 최신 데이터가 아닌 캐시된 데이터를 제공할 수 있습니다.
- 메모리 사용량 vs. 디스크 I/O: 메모리에 더 많은 데이터를 캐시하면 디스크 I/O를 줄일 수 있지만, 메모리 사용량이 증가합니다.
- 응답 시간 vs. 처리량: 개별 쿼리의 응답 시간을 줄이기 위해 리소스를 집중할 경우, 전체 시스템의 처리량이 감소할 수 있습니다.
동기식 처리 (Synchronous Processing)
개념
- 동기식 처리는 작업이 완료될 때까지 다음 작업을 시작하지 않는 방식입니다. 즉, 한 작업이 완료되어야만 그 다음 작업을 수행할 수 있습니다.
장점
- 데이터 일관성: 모든 작업이 순차적으로 완료되기 때문에 데이터 일관성이 보장됩니다.
- 예측 가능성: 작업이 완료될 때까지 기다리기 때문에 예측 가능한 응답 시간을 제공합니다.
단점
- 응답 시간 증가: 작업이 완료될 때까지 기다려야 하므로 전체 응답 시간이 증가할 수 있습니다.
- 효율성 저하: I/O 작업이 많은 경우, CPU가 유휴 상태로 대기하게 되어 자원 활용이 비효율적일 수 있습니다.
예시
-- 동기식으로 데이터를 삽입하고 커밋
BEGIN TRAN
INSERT INTO Players (PlayerID, PlayerName, JoinDate) VALUES (1, 'Alice', '2024-07-12')
COMMIT비동기식 처리 (Asynchronous Processing)
개념
- 비동기식 처리는 작업이 완료될 때까지 기다리지 않고 다음 작업을 수행하는 방식입니다. 즉, 작업이 백그라운드에서 실행되는 동안 다른 작업을 계속 수행할 수 있습니다.
장점
- 높은 처리량: 여러 작업을 병렬로 처리할 수 있어 전체 처리량이 증가합니다.
- 자원 활용 효율성: I/O 작업이 완료되기를 기다리지 않으므로 CPU와 기타 자원을 효율적으로 사용할 수 있습니다.
단점
- 데이터 일관성 관리 필요: 비동기식 처리는 데이터 일관성을 보장하기 어려울 수 있으며, 이를 관리하기 위한 추가 메커니즘이 필요합니다.
- 복잡성 증가: 비동기식 처리를 구현하고 관리하는 데 추가적인 복잡성이 발생합니다.
예시
-- 비동기식으로 데이터를 삽입하고 트랜잭션 로그를 나중에 디스크에 기록
BEGIN TRAN
INSERT INTO Players (PlayerID, PlayerName, JoinDate) VALUES (1, 'Alice', '2024-07-12')
-- 커밋은 비동기적으로 처리
COMMIT동기식 및 비동기식 처리의 트레이드오프
동기식 처리의 트레이드오프
- 성능 저하: 작업이 순차적으로 처리되기 때문에 응답 시간이 느려질 수 있습니다.
- 안정성: 데이터 일관성이 높아지고 예측 가능한 결과를 제공합니다.
비동기식 처리의 트레이드오프
- 성능 향상: 병렬 처리가 가능하여 전체 시스템 성능이 향상될 수 있습니다.
- 복잡성 증가: 데이터 일관성을 유지하기 위한 추가적인 메커니즘이 필요합니다.
설명 그림
아래 그림은 동기식 처리와 비동기식 처리의 차이를 보여줍니다.


결론
동기식 처리와 비동기식 처리의 선택은 시스템 요구사항과 트레이드오프를 고려하여 결정해야 합니다.
동기식 처리는 데이터 일관성과 예측 가능성을 제공하지만 성능이 저하될 수 있으며,
비동기식 처리는 성능을 향상시킬 수 있지만 데이터 일관성 유지와 구현의 복잡성을 증가시킬 수 있습니다.
데이터베이스 시스템에서 적절한 처리를 선택하는 것은 성능 최적화와 데이터 일관성 유지 사이에서 균형을 맞추는 중요한 결정입니다.

다시 처음으로 돌아가 전부 한번씩 공부해보자
'DB > MS-SQL' 카테고리의 다른 글
| 21. [MS-SQL] 인덱스부터 포괄열까지 이해하기 (1) | 2024.12.15 |
|---|---|
| 19. [MS-SQL] 정규화 역정규화 사이에서 고민 (0) | 2024.06.19 |
| 18. [MS- SQL] 인덱스 힌트 (인덱스 사용 강제하기) (0) | 2024.06.05 |
| 17. [MS-SQL] 인덱스가 걸려있는 칼럼 조회하기 (0) | 2024.06.05 |
| 16. [MS-SQL] 논클러스터 인덱스(Non-Clustered Index) (1) | 2024.05.31 |
